MapAction volunteer Chris Jarvis and a colleague from the Americas Support Team.
MapAction has been involved in the response to the earthquake that took place in Haiti on 14 August, helping our partners with data processing, analysis and mapping. This has helped those coordinating operational teams to understand what types of aid are needed in different locations and what other organisations are already doing to help. At the time of writing, this work is ongoing.
At the end of August, we scaled up our support to the UN Disaster Assessment & Coordination (UNDAC) and other responding organisations. Two MapAction volunteers traveled to Haiti to provide in-person assistance, supported remotely by our wider team. As well as using their annual leave to do this, both were required to self-isolate for 10 days after returning to the UK, in accordance with COVID rules. We are grateful to them both for their invaluable efforts.
This StoryMap looks at some of the maps that have so far been created during the response to the earthquake and how they have been used to help the situation on the ground.
By Egor Zverev Egor is working with us temporarily through Google’s Summer of Code programme.
How could I apply my programming and data science skills to make the world a better and safer place? I’ve been struggling to figure that out for quite some time, and finally after three years of studying computer science at MIPT in Moscow, I found an opportunity to fulfil my dreams.
Hi, I’m Egor, and I want to write about the impact I am making while working on my Google Summer of Code (GSoC) project at MapAction!
I decided to join the GSoC programme as I felt it was an amazing opportunity to spend my summer working on a real-world open-source project. The programme offered me 202 organisations and over a thousand projects to choose from, but MapAction stood out as the only humanitarian organisation among them, so the choice was obvious to me. I faced some stiff competition as 25 other candidates applied for this role, so I am so grateful for the opportunity to join MapAction in its mission.
My GSoC began with a bonding period, and even that was amazing! I was introduced to MapAction during one of its many training days. I listened to various lectures given by the MapAction team. I was especially inspired by Hannah’s presentation as she is working at both MapAction and UN OCHA (the UN Office for the Coordination of Humanitarian Affairs) where she’s developing an anticipatory action framework. Talking to her was a fascinating part of my GSoC experience as it made me think hard about how I could help solve some of the world’s problems. Following that, I had a week of meeting various people from MapAction. Each encounter was special in its own way. After my first week, I already felt like I was a part of the team, an ideal time to start coding.
I have been working on the data pipeline project: a MapAction tool to automate the acquisition and transformation of data. During the early stages of emergency response, it’s crucial to gather all necessary data as quickly as possible. My goal was to extend the pipeline from three to 22 data products. This will allow for visualisation of much more infrastructure and landscape features etc. After adding the initial five products, I realised that the code required a serious refactoring as it was quite unwieldy and difficult to deal with. During the first stage I managed to fix many local problems and reduced the total amount of code by almost 30%. Going forward, I am planning to redesign the entire pipeline’s architecture and implement a new design. After this I hope to add unit tests to ensure the code is correct.
As most of MapAction’s developers are volunteers who only work for a couple of hours per week, a simplified pipeline will make it much easier for both them and any newcomers to make sense of it and use it. My work has also increased the readability of the code and made future pipeline development much faster.
In summary, not only have I already added many valuable datasets to the pipeline that will allow MapAction volunteers to easily understand the locations of rivers, airports, country boundaries, etc. I am also bringing fundamental changes to the project that will make the life of MapAction’s volunteers much easier. I feel very proud of the impact I am making and it is an honour for me to spend my summer working on this project.
We are proud to be supporting the delivery of an online course in crisis mapping in the Caribbean this month. The training course will involve around 50 disaster management professionals from across the Caribbean and is in partnership with the Caribbean Disaster Emergency Management Agency (CDEMA), with input from the Humanitarian OpenStreetMap Team (HOT).
This is the second time the online course has been run, and we used our extensive deployment and training experience in the design and development of it.
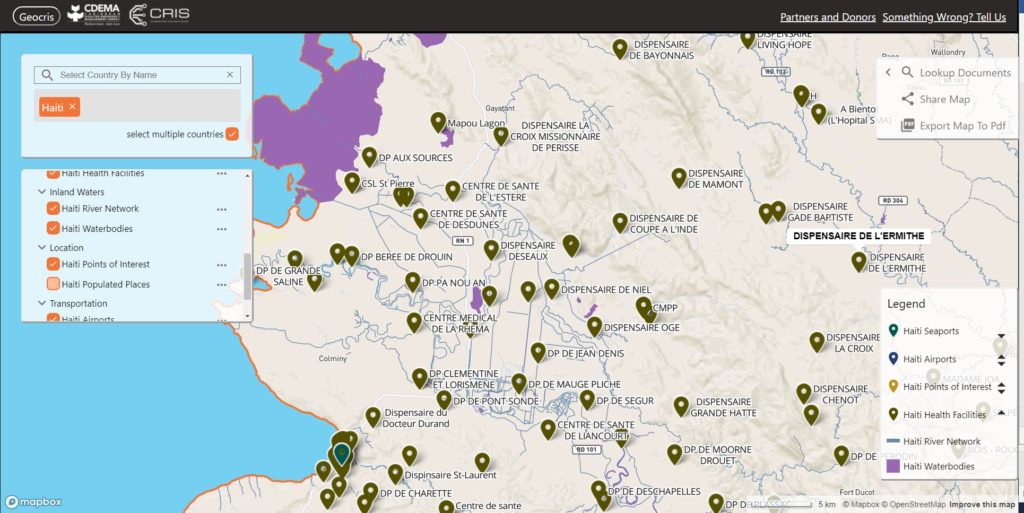
Screenshot of the GeoCRIS showing a map of part of Western Haiti with several map layers selected
As well as learning the principles of disaster mapping for response and resilience and OpenStreetMap data entry, the participants are practicing effective use of the GeoCRIS. This is the new regional repository for geospatial data needed for risk and hazard mapping, disaster preparedness and response operations. As MapAction was involved in setting up the GeoCRIS, we are well placed to design and deliver this training.
The month-long course also includes a disaster simulation exercise in which the students will have the opportunity to deploy their newly acquired skills in a realistic emergency scenario. Additionally, two members of MapAction’s Caribbean volunteer team who have both recently been involved in the response to the La Soufrière volcanic eruption will be running a live session to share their real-world experiences of emergency mapping in the region and answer questions.
We’re grateful to USAID’s Bureau for Humanitarian Assistance (BHA) for funding this activity as part of our ongoing programme to improve the ways in which geographical information systems (GIS), mapping and spatial analysis are used in humanitarian emergencies.
When MapAction triggers an emergency response, the first step is for a team of staff and volunteers to begin what is known as a “data scramble”. This is the process of gathering, organising, checking, and preparing the data required to make the first core maps that emergency response teams will need, which will also be used as the basis for subsequent situational mapping.
Traditionally, the aim was to complete this data collection as quickly as possible, to get as much data as possible that was relevant to the emergency. However, due to the time-sensitive nature of this work, the team is often unable to dissect in detail the different data source options, processes, and decisions involved as they ready the data for ingestion into maps.
What if they weren’t constrained by time during the data scramble? What if they could deconstruct the procedure and examine the data source selection, scrutinise the processing applied to every data type, and explore the ways that these steps could be automated? To answer these questions, the volunteers at MapAction, with support from the German Federal Foreign Office, have been tackling a stepping-stone project leading towards automation, dubbed the “slow data scramble”. We called it this because it is a methodical and meticulous deconstruction of a rapid data scramble as carried out in a sudden-onset emergency.
Data gaps
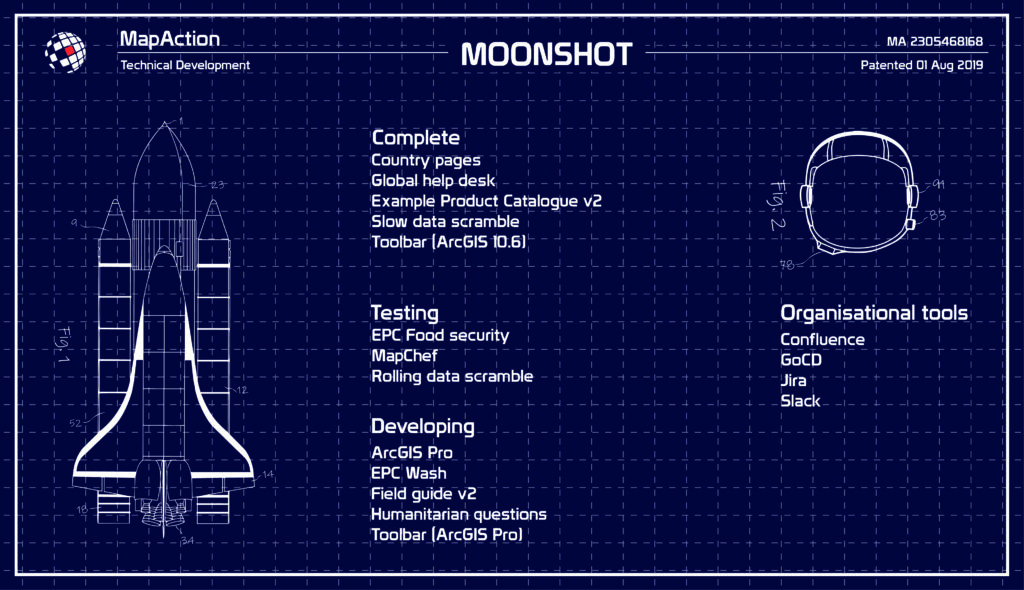
As part of our Moonshot, MapAction is looking to automate the creation of nine core maps that are needed in every response, freeing up vital time for volunteers during an emergency, and, perhaps more importantly, identifying data issues and gaps well before the onset of an emergency. Towards this end, we have just released version 1.1 of our software MapChef, which takes processed data and uses it to automatically create a map. However, even with MapChef up and running, there is still a large gap in our pipeline: how do you get the data in the first place? How do you make sure it’s in the right state to go into the map? And which data do you actually need?
The volunteer team created and led a project intended to answer precisely the above questions, with the goal of scoping out the pipeline. This would include writing the code for completing the above operations, although not yet packaging things together in a smooth way – that is saved for a future pipeline project.
Selecting the right components
The first step was to determine what data is required to produce the core maps. The volunteers identified a list of 23 ingredients that make up these maps, which we call “data requirements”. These range from administrative boundaries to roads, and from airports to hillshading (a technique for creating relief maps). To complicate matters, each data artefact had multiple possible sources. For example, administrative boundaries could come from the Common Operational Datasets (CODs, distributed by the Humanitarian Data Exchange), the Database of Global Administrative Areas (GADM), or geoBoundaries.
“The scale and extent of data available for just a single country administrative area alone is staggering.”
James Wharfe, MapAction volunteer
Next, the team needed to address how to obtain the data and ready it for further processing. Normally, when volunteers make maps by hand, they go to the website associated with each artefact, manually download it, and tweak it by hand until it is ready to be used in a map. However, with the pipeline this all needs to be automated.
To approach this considerable undertaking, the team divided up the work into small, digestible tasks, meeting fortnightly to discuss progress, answer each other’s questions, and assign new tasks. This work continued diligently for seven months, at the end of which they had a functional and documented set of code snippets capable of automatically downloading and transforming the data required for all artefacts.
Overcoming challenges
There were numerous challenges along the way that the team needed to overcome. Understanding the differences between the various data sources proved a significant hurdle. “The scale and extent of data available for just a single country administrative area alone is staggering,” noted volunteer James Wharfe. (Indeed, this data landscape is so complex that it merits its own post – stay tuned for a blog about administrative boundaries as part of our upcoming “Challenges of…” series.)
One particular data source that seemed to crop up everywhere was OpenStreetMap (OSM). Almost all of the data requirements in the slow data scramble are available from OSM, making it a key data source. However, given the sheer detail and size of the OSM database – 1,37 terabytes as of 1 Feb, 2021(source) – there are several difficulties involved when working with the data.
For the download step, the team decided to invoke the Overpass API, and create a Python method to abstract the complex query language down to some simple YAML files with OSM tag lists. Next, the downloaded data needed to be converted from the OSM-specific PBF format to a shapefile, which is the type of data expected by MapChef. Several solutions for this exist: to name a few, Imposm, PyDriosm, Osmosis, OSM Export Tool, and Esy OSM PBF. For this project, we decided to use GDAL, however, we certainly plan on exploring the other options, and hope to eventually host our own planet file.
Code control
Even though the goal of the slow data scramble was not to produce production-quality code, the team still used Git to host their version-controlled code. According to Steve Penson, the volunteer leading the project, “The collaborative and explorative nature of the project meant Git was incredibly useful. With each volunteer tackling significantly different challenges, establishing a strong code control setup made our weekly reviews far easier.”
The team also used the opportunity to extend their Python skills, with a particular focus on GeoPandas, which enables some of the more intricate data transformations that are normally performed by mainstream desktop GIS tools.
Additionally, the group used this work to explore the concept of DAGs, directed acyclical graphs. This term refers to the building blocks of any pipeline: a recipe, or series of steps, that you apply to your data. There are scores of packages available to assist with pipeline development, but to start, the team decided to use a simple workflow management system called Snakemake. Snakemake works by using Makefiles to connect the expected input and output files across multiple pipeline stages. Although, in the end, the team decided it was not the best solution for scaling up to the real pipeline (which is now being developed with Airflow), they agreed that using Snakemake was a great stepping stone to becoming familiar with this key concept.
Working together
Finally, before COVID-19 hit, MapAction’s dedicated volunteers were accustomed to meeting in person once a month – a commitment that led to many enjoyable shared moments and close friendships. This positive and much-loved aspect of being a volunteer at MapAction has unfortunately been hindered by the pandemic. Although still conducted fully remotely, the slow data scramble offered the chance to regularly meet, share expertise, motivate and encourage each other, and work together. Volunteer Dominic Greenslade said it well: “MapAction volunteers are amazing people, and the ability to spend so much time getting to further these friendships was a great bonus”.
MapAction has been chosen as one of 202 organisations taking part in Google’s 2021 Summer of Code, a global programme that aims to bring student developers into open source software development. As part of the scheme, which has now entered into its 17th year, students can apply for placement projects from 202 open source entities, with their time paid for by Google. MapAction is one of 31 organisations taking part for the first time.
Since launching, over 16,000 students across 111 countries have taken part by working with an open source organisation on a 10-week programming project during their summer break from studies. Google Summer of Code is open to students who are age 18 and older and enrolled in a post-secondary academic programme in most countries. As MapAction is one of the only companies taking part from the humanitarian charity sector, it’s a great opportunity to highlight the importance of technology advances to our work.
As part of our Moonshot initiative, two students will be helping us with our goal of automating the production of core maps needed in any humanitarian crisis, for 20 priority countries. Being able to automate these maps means essential contextual and reference information about, among other things, the local environment, population and infrastructure, is immediately available when needed in the best possible quality. The students will be working with MapChef, our Python-based map automation tool, and our MVP pipeline framework for automated data acquisition and processing. As our capability grows, we intend to use these systems to identify data gaps at regional levels.
Take a look at our project ideas for the Google Summer of Code. Applications officially open on 29 March and we anticipate a lot of interest.
Over 50 authors, including two MapAction team members, have contributed their expertise and insight about working in health emergencies to a new handbook for humanitarian professionals.
Addressing the multi-faceted challenges of an international deployment, the book provides technical medical information as well as insights into the challenging environments volunteers often work in and the cultural differences that influence risk communication.
The book is divided into two halves, with the first providing an overview of the international architecture and inter-disciplinary environment within which health emergency responses occur. These include the organisations, principles, frameworks and themes that every health professional deploying aboard should be aware of. The second half of the book provides practical advice to help professionals survive and thrive during their mission. Chapters include how to prepare for a deployment, such as arrangements that should be taken care of ahead of departure, and suggestions on what to pack.
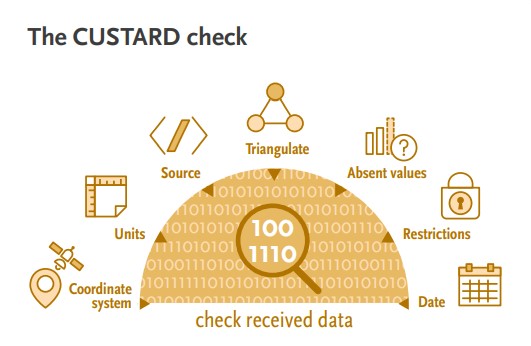
Checks to incoming data can easily be remembered using the acronym CUSTARD.
Information management & visualisation
As part of their contribution (in chapter 3, starting at page 200), MapAction’s Matt Sims and Alan Mills shared how important data visualisations are in making well-informed decisions and the importance of identifying information gaps to ensure those who may need assistance are not overlooked.
Also covered in their chapter are the questions that responders should be asking themselves when handling data, such as whether it identifies the location of vulnerable individuals or groups; how the data is stored and protected; and what will be produced from the data, among other considerations.
Hard copies of the book can be requested by emailing the Robert Koch Institut.
What is MapAction’s ‘humanitarian data landscape?’ At MapAction, we’re working to put data at the centre of how we provide products and services to the humanitarian sector. MapAction’s data scientist, Monica Turner, recently posted about the work she does in this new role. However, data is a big (and sometimes loaded) term. So what does ‘data’ mean to MapAction? We asked Hannah Ker, MapAction’s Data Scientist whilst Monica is on maternity leave, to explain.
During a humanitarian crisis, it is vitally important for responders to have information such as which areas are most affected, where vulnerable populations exist and where relevant infrastructure & services (such as healthcare facilities) are located. MapAction provides information products (such as maps) to our partners to help them address these information needs. Unsurprisingly the vast majority of data that we work with at MapAction is geospatial. We aim to use geospatial techniques, such as cartography, to make complex data rapidlly accessible to those responding to humanitarian crises.
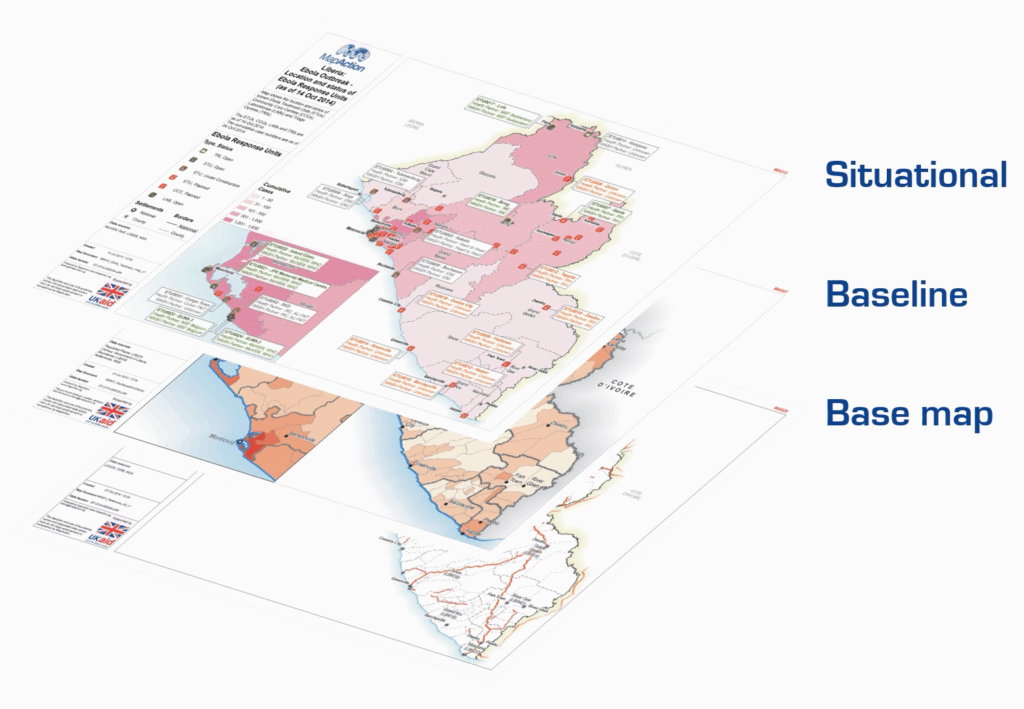
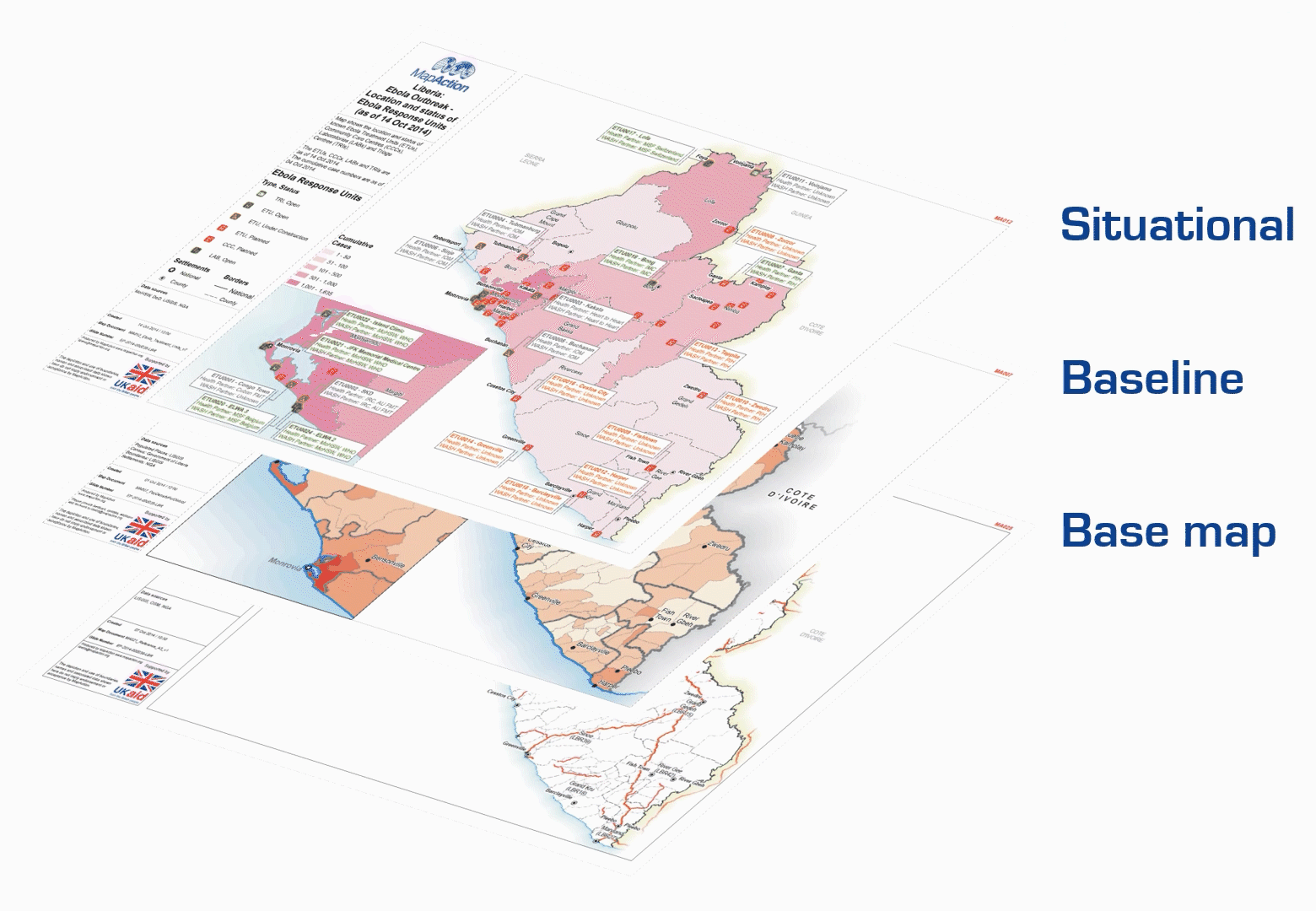
The ‘Layers of data’ page (see diagram below) from our Example Product Catalogue provides a useful framework for thinking about how many different datasets are processed and combined into a meaningful final product.
Firstly, we can think of the data that is input to our basemap or initial reference map of a given area. This data often reflects features such as administrative boundaries, land elevation, settlements, and transportation infrastructure. Secondly, we have baseline data that provides demographic information about the area of interest, such as population numbers and numbers of schools.
Our last data layer includes situational information that is relevant to the humanitarian context at hand. The kinds of data relevant for this layer can vary significantly depending on the circumstances. This data is also likely to be the most dynamic and temporally sensitive. For example, it may be used to show change over time as a crisis evolves.
All of this data can come from a variety of sources. The Humanitarian Data Exchange (HDX), developed and maintained by the UN OCHA Centre for Humanitarian Data, is a repository that holds over 17,000 datasets from more than 1,300 different sources. These datasets come from what we might think of as ‘authoritative’ sources of information, such as the World Bank or the World Food Programme.
In particular, MapAction frequently uses the Common Operational Datasets of Administrative Boundaries (COD-AB) that are published and maintained by the UN Office for the Coordination of Humanitarian Affairs (OCHA). It can be challenging to access complete and up-to-date administrative boundary data, so the CODs attempt to provide standardised, high quality data that can be used to support humanitarian operations.
OpenStreetMap (OSM) also provides a valuable source of geospatial data. This ‘Wikipedia of maps’ is an entirely crowdsourced map of the world. In theory, anyone, anywhere in the world (with an internet connection) can contribute to OSM. At MapAction, we use OSM as a source of data for features such as settlements and transportation infrastructure. MapAction is a partner of the Missing Maps project, hosted by OSM which seeks to crowd source the gaps in maps in available maps.
So why can’t we just use maps that already exist, like Google Maps?, one might ask. Why all these complex data layers? Why spend so much time finding data when it’s already all there?
Platforms such as Google Maps, Waze, and Apple Maps are commonly used as day-to-day navigation tools for people in many parts of the world. However, such existing tools do not provide the flexibility that is often required when managing and presenting geospatial data in humanitarian scenarios. As these tools are privately-developed, individuals and organisations do not always have the ability to manipulate or style the underlying data to suit their needs. These platforms were not created specifically for humanitarian use-cases, and so may not always include the information that meets the operational requirements of humanitarian contexts, such as locations of damaged buildings or the extent of a flood.
OSM’s Humanitarian map style, for example, shows some of the unique data styling that may be required in humanitarian contexts. Moreover, there are many parts of the world with human settlements that are not present (or poorly represented) on existing maps, as is demonstrated by efforts from organisations such as the Humanitarian OpenStreetMap Team and the Missing Maps initiative. These challenges mean that there is no existing ‘one size fits all’ mapping platform that is capable of providing and presenting all of the information that is needed in humanitarian contexts.
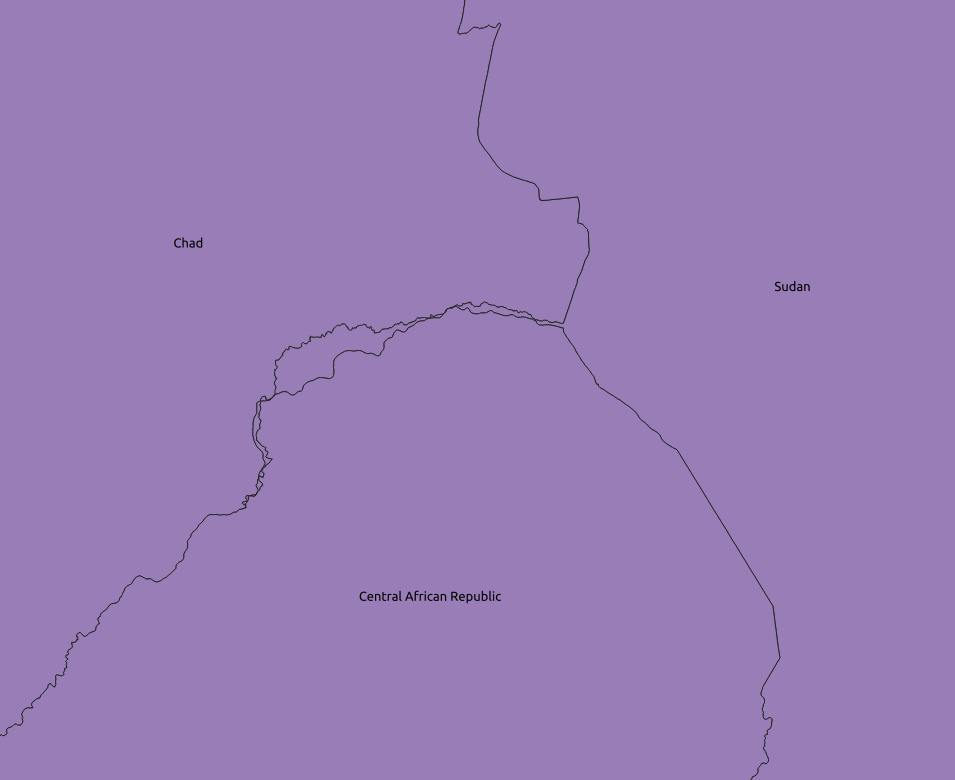
Finding high quality geospatial data is an ongoing challenge for us at MapAction. Geospatial data quality is a multifaceted concept, and includes dimensions such as up-to-dateness, positional accuracy, logical consistency, and completeness. The image below, for example, shows a geometry problem that we often face with administrative boundary data. Notice the gap in the border between Chad and the Central African Republic. Lack of standardisation in this data between different countries and organisations, or out of date data can result in such misalignment. Due to the political sensitivity that is associated with boundary data, it is important to ensure that the data that we use is as accurate as possible.
Our ongoing work around the Moonshot project seeks to develop tools that can help us to automatically detect and address quality issues such as these. Keep an eye out for future blog posts where we will address some of these technical challenges in greater detail.
At the end of the day, we’re working to make complex situations better understood. Humanitarian crises are incredibly complex, and accordingly, can be associated with complex datasets and information. By selecting high quality datasets and visualising them in clear and accessible ways, we intend for our humanitarian partners to be able to make informed decisions and deliver effective aid to those in need.
MapAction’s Data Scientist is funded by the German Federal Foreign Office (GFFO), but the views and opinions above do not necessarily represent those of the GFFO.
MapAction has been collaborating for a number of years with French NGO and fellow humanitarian information management specialists CartONG.
In addition to our operational activities, we thought it would be worthwhile to pool our collective knowledge to create an informative article. The ten-minute read aims to give some helpful tips for people creating maps intended to assist humanitarian responses to the Corona virus and other pandemics.
Between us, we have a lot of experience of using geospatial analysis and visualisations to inform decision-making in this and previous epidemics, such as Ebola, as well as the current pandemic. We wanted to share this knowledge more widely and felt that, by working together, we could create something really useful and reach more people. Although it was written with pandemics in mind, many of the points apply to all kinds of map making.
You can read the article on the CartONG blog below.
This project was co-funded by the French Development Agency (AFD) and the H2H Network’s H2H Fund, the latter supported by UK aid from the UK government.
History will always underscore how landing on the moon represented a significant milestone in the space race, yet what is often less spoken about is the number of technologies that might not have ever made it without space travel.
These include the all-important ability to take pictures on our phone, thanks to the technology originally created by a team at the Jet Propulsion Laboratory, and the technique used to develop diamond-hard coatings for aerospace systems that can now be found on scratch-resistant spectacles. Inventions that originally started life with a bigger purpose but have filtered down into solving some of the challenges in our everyday lives.
This brings us onto MapAction’s own Moonshot initiative – an ambitious programme of work encompassing step changes in the way we use different technologies in the course of our work. This includes things like how we triage, assign and manage the requests for support we receive, and how we can automate certain repeat activities.
One of the first projects we are working on within the Moonshot programme will enable us to produce seven to nine key maps for 20 of the world’s most vulnerable countries automatically, using technology we’re developing that will provide benefits for many years to come. This is being funded through our partnership with the German Federal Foreign Office.
In the humanitarian sector, a perennial challenge is access to high-quality data. This need is even more acute in the chaotic aftermath of a humanitarian emergency, when data and maps are crucial to make rapid sense of the situation and plan the best response to save lives and minimise suffering.
In the early hours of a crisis, one of the first tasks facing our team is to produce standardised ‘core’ maps that will be used throughout the response, regardless of the nature of the emergency. These provide contextual and reference information about, among other things, the local environment, population and infrastructure. Sometimes they are created under difficult on-the-ground conditions or with incomplete information. Once they are in place, they are used to create additional situation-specific maps by layering on top evolving information about the extent and impacts of the emergency and the humanitarian response.
As MapAction has made maps in hundreds of emergencies, it has become apparent that, in creating these foundational core maps, there are many repeatable, generalised tasks that could be handled much more quickly by a machine, achieving in seconds what used to take hours. This would give humanitarian decision-makers the orientation information they need immediately, and free up our specialist volunteers for actively assessing and engaging with the situation at hand and performing the mapping tasks that only humans can do.
Moreover, by shifting the focus from reactive to proactive data sourcing and map production, we can ensure we provide the best maps possible – not just the best maps, given the time and data available and the prevailing circumstances in the midst of a humanitarian emergency.
Many countries, particularly low and middle-income countries, are likely to have data gaps, and they are often also the countries that may have the least resilience to emergencies such as droughts or earthquakes. Identifying and addressing these data gaps in advance is a big part of the Moonshot project, and something that will have benefits for the humanitarian sector as a whole.
Like the proverbial needle in the haystack, important data can exist within a subset of a much larger dataset and accessing it can be tricky. Finding a gap is even more difficult, as you’re looking for an unknown entity that isn’t there. The technology we’re developing for the Moonshot will help us to identify the hard-to-see data gaps and quality issues that currently exist. By discovering these, we can pinpoint what information will be needed to ensure a complete map and then work with partners around the world to proactively put in place missing data or improve what currently exists.
The initial goal of the Moonshot is to publish 180 core maps (nine for each of the 20 vulnerable countries identified at the beginning of the project). The same processes will then be applied to other countries and, eventually, to other types of automated maps beyond these core ones. This means we will ultimately be in a position to expand our understanding and quality assessment processes for more data types. New opportunities and routes of travel are likely to emerge as the project develops.
The ambition is big, but the possibilities that will result from achieving this goal will fundamentally change the way we approach map creation in the humanitarian sector in the future.
In a series of blogs over the next few months, we will share the story of this work as it unfolds, as well as diving down deeper into specific elements of it.
MapAction volunteers have been supporting the World Health Organization (WHO) in Libya and Chad to process and map data about health and sanitation services, in order to support the response to COVID-19.
The volunteers have been working remotely, alongside each country’s health cluster (networks of WHO partners that work together to relieve suffering and save lives in humanitarian emergencies). They have been helping to identify and map what healthcare, water and sanitation services and aid are being provided, by whom, when and where. This is known as 4W mapping and is important to help identify gaps and avoid duplication.
We are now looking at providing similar assistance to WHO in other parts of North and Central Africa.
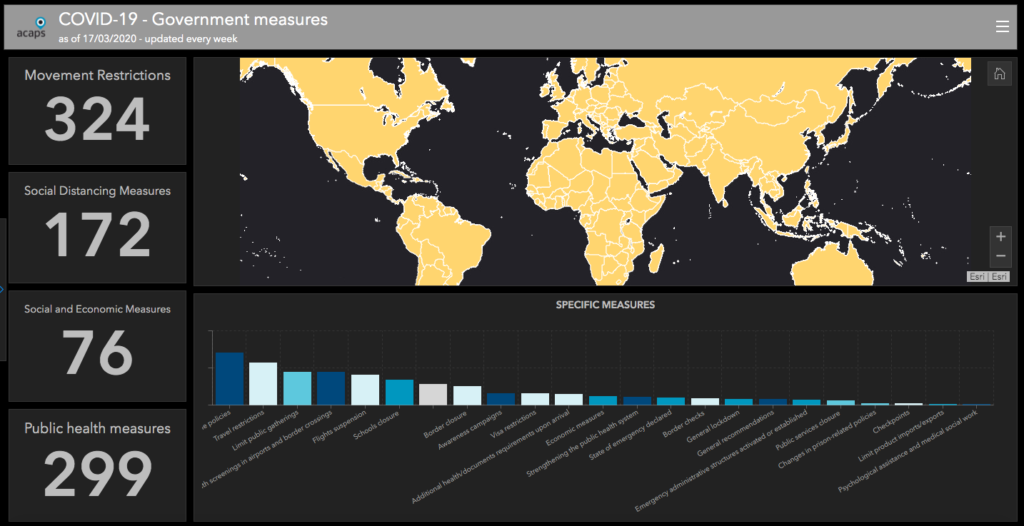
We’ve helped ACAPS to put together a dashboard showing government measures being taken around the world. Data can be filtered by region, country, type of measure and timeframe.
We will be updating this twice a week. In the meantime ACAPS, MapAction and other organisations are looking at further topics to develop analysis for.
This week, a MapAction volunteer has been participating in discussions and strengthening relationships with our partners at the International Search and Rescue Advisory Group (INSARAG) Information Management Working Group and Team Leaders meetings in Santiago, Chile. These conversations enable us to continuously improve how we visualise data collected by INSARAG teams.
Thanks to the USAID Office of U.S. Foreign Disaster Assistance for supporting our participation, as part of our joint programme to improve the ways in which geographical information systems (GIS), mapping and spatial analysis are used in humanitarian emergencies.










.jpg){kind=link}