By Egor Zverev Egor is working with us temporarily through Google’s Summer of Code programme.
How could I apply my programming and data science skills to make the world a better and safer place? I’ve been struggling to figure that out for quite some time, and finally after three years of studying computer science at MIPT in Moscow, I found an opportunity to fulfil my dreams.
Hi, I’m Egor, and I want to write about the impact I am making while working on my Google Summer of Code (GSoC) project at MapAction!
I decided to join the GSoC programme as I felt it was an amazing opportunity to spend my summer working on a real-world open-source project. The programme offered me 202 organisations and over a thousand projects to choose from, but MapAction stood out as the only humanitarian organisation among them, so the choice was obvious to me. I faced some stiff competition as 25 other candidates applied for this role, so I am so grateful for the opportunity to join MapAction in its mission.
My GSoC began with a bonding period, and even that was amazing! I was introduced to MapAction during one of its many training days. I listened to various lectures given by the MapAction team. I was especially inspired by Hannah’s presentation as she is working at both MapAction and UN OCHA (the UN Office for the Coordination of Humanitarian Affairs) where she’s developing an anticipatory action framework. Talking to her was a fascinating part of my GSoC experience as it made me think hard about how I could help solve some of the world’s problems. Following that, I had a week of meeting various people from MapAction. Each encounter was special in its own way. After my first week, I already felt like I was a part of the team, an ideal time to start coding.
I have been working on the data pipeline project: a MapAction tool to automate the acquisition and transformation of data. During the early stages of emergency response, it’s crucial to gather all necessary data as quickly as possible. My goal was to extend the pipeline from three to 22 data products. This will allow for visualisation of much more infrastructure and landscape features etc. After adding the initial five products, I realised that the code required a serious refactoring as it was quite unwieldy and difficult to deal with. During the first stage I managed to fix many local problems and reduced the total amount of code by almost 30%. Going forward, I am planning to redesign the entire pipeline’s architecture and implement a new design. After this I hope to add unit tests to ensure the code is correct.
As most of MapAction’s developers are volunteers who only work for a couple of hours per week, a simplified pipeline will make it much easier for both them and any newcomers to make sense of it and use it. My work has also increased the readability of the code and made future pipeline development much faster.
In summary, not only have I already added many valuable datasets to the pipeline that will allow MapAction volunteers to easily understand the locations of rivers, airports, country boundaries, etc. I am also bringing fundamental changes to the project that will make the life of MapAction’s volunteers much easier. I feel very proud of the impact I am making and it is an honour for me to spend my summer working on this project.
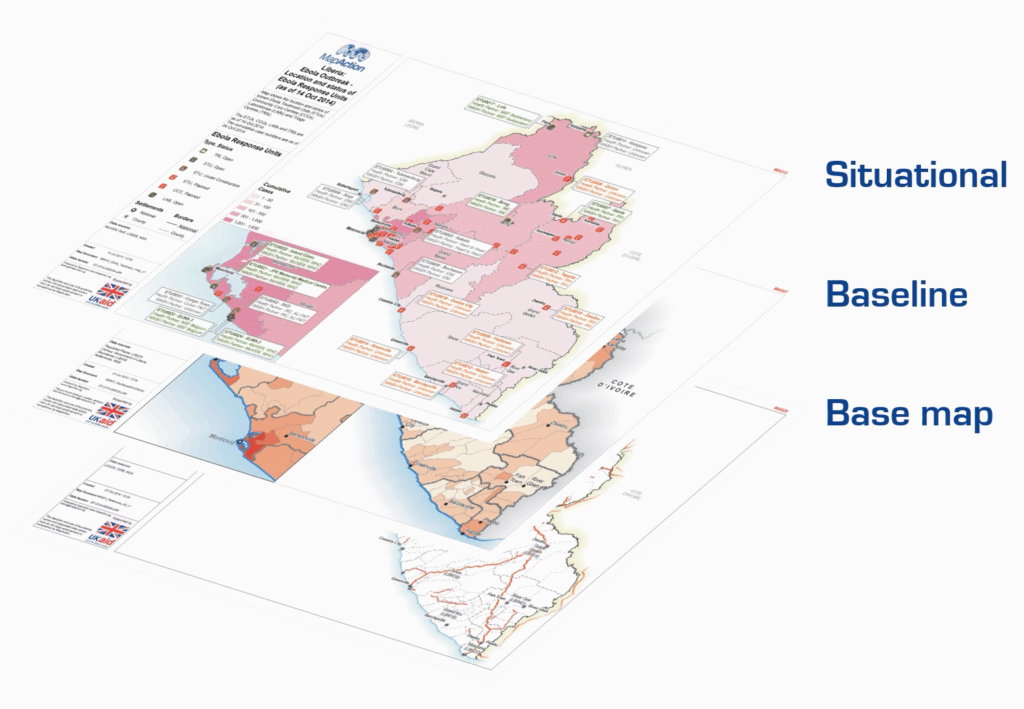
When MapAction triggers an emergency response, the first step is for a team of staff and volunteers to begin what is known as a “data scramble”. This is the process of gathering, organising, checking, and preparing the data required to make the first core maps that emergency response teams will need, which will also be used as the basis for subsequent situational mapping.
Traditionally, the aim was to complete this data collection as quickly as possible, to get as much data as possible that was relevant to the emergency. However, due to the time-sensitive nature of this work, the team is often unable to dissect in detail the different data source options, processes, and decisions involved as they ready the data for ingestion into maps.
What if they weren’t constrained by time during the data scramble? What if they could deconstruct the procedure and examine the data source selection, scrutinise the processing applied to every data type, and explore the ways that these steps could be automated? To answer these questions, the volunteers at MapAction, with support from the German Federal Foreign Office, have been tackling a stepping-stone project leading towards automation, dubbed the “slow data scramble”. We called it this because it is a methodical and meticulous deconstruction of a rapid data scramble as carried out in a sudden-onset emergency.
Data gaps
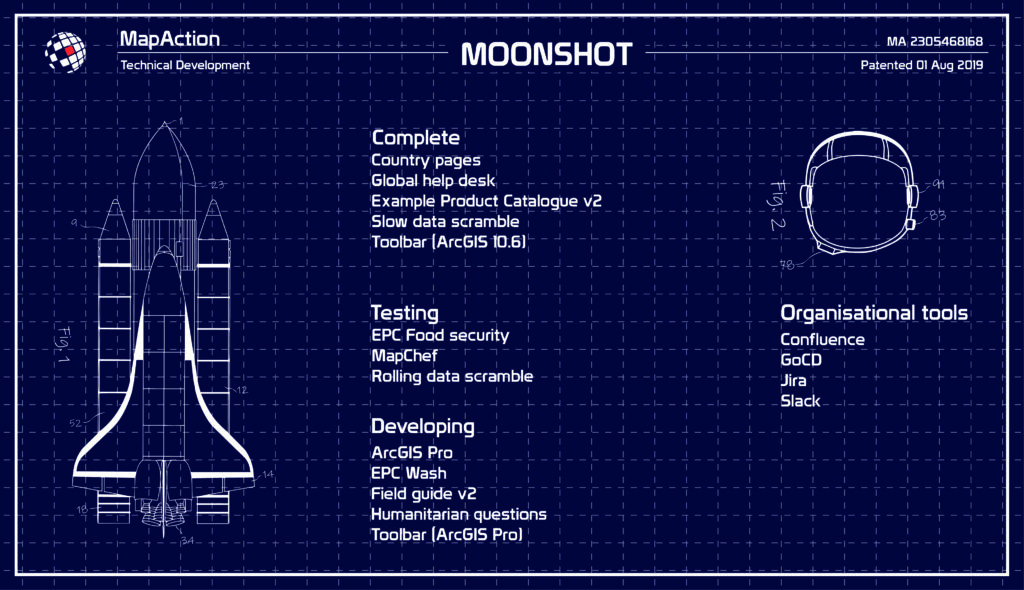
As part of our Moonshot, MapAction is looking to automate the creation of nine core maps that are needed in every response, freeing up vital time for volunteers during an emergency, and, perhaps more importantly, identifying data issues and gaps well before the onset of an emergency. Towards this end, we have just released version 1.1 of our software MapChef, which takes processed data and uses it to automatically create a map. However, even with MapChef up and running, there is still a large gap in our pipeline: how do you get the data in the first place? How do you make sure it’s in the right state to go into the map? And which data do you actually need?
The volunteer team created and led a project intended to answer precisely the above questions, with the goal of scoping out the pipeline. This would include writing the code for completing the above operations, although not yet packaging things together in a smooth way – that is saved for a future pipeline project.
Selecting the right components
The first step was to determine what data is required to produce the core maps. The volunteers identified a list of 23 ingredients that make up these maps, which we call “data requirements”. These range from administrative boundaries to roads, and from airports to hillshading (a technique for creating relief maps). To complicate matters, each data artefact had multiple possible sources. For example, administrative boundaries could come from the Common Operational Datasets (CODs, distributed by the Humanitarian Data Exchange), the Database of Global Administrative Areas (GADM), or geoBoundaries.
“The scale and extent of data available for just a single country administrative area alone is staggering.”
James Wharfe, MapAction volunteer
Next, the team needed to address how to obtain the data and ready it for further processing. Normally, when volunteers make maps by hand, they go to the website associated with each artefact, manually download it, and tweak it by hand until it is ready to be used in a map. However, with the pipeline this all needs to be automated.
To approach this considerable undertaking, the team divided up the work into small, digestible tasks, meeting fortnightly to discuss progress, answer each other’s questions, and assign new tasks. This work continued diligently for seven months, at the end of which they had a functional and documented set of code snippets capable of automatically downloading and transforming the data required for all artefacts.
Overcoming challenges
There were numerous challenges along the way that the team needed to overcome. Understanding the differences between the various data sources proved a significant hurdle. “The scale and extent of data available for just a single country administrative area alone is staggering,” noted volunteer James Wharfe. (Indeed, this data landscape is so complex that it merits its own post – stay tuned for a blog about administrative boundaries as part of our upcoming “Challenges of…” series.)
One particular data source that seemed to crop up everywhere was OpenStreetMap (OSM). Almost all of the data requirements in the slow data scramble are available from OSM, making it a key data source. However, given the sheer detail and size of the OSM database – 1,37 terabytes as of 1 Feb, 2021(source) – there are several difficulties involved when working with the data.
For the download step, the team decided to invoke the Overpass API, and create a Python method to abstract the complex query language down to some simple YAML files with OSM tag lists. Next, the downloaded data needed to be converted from the OSM-specific PBF format to a shapefile, which is the type of data expected by MapChef. Several solutions for this exist: to name a few, Imposm, PyDriosm, Osmosis, OSM Export Tool, and Esy OSM PBF. For this project, we decided to use GDAL, however, we certainly plan on exploring the other options, and hope to eventually host our own planet file.
Code control
Even though the goal of the slow data scramble was not to produce production-quality code, the team still used Git to host their version-controlled code. According to Steve Penson, the volunteer leading the project, “The collaborative and explorative nature of the project meant Git was incredibly useful. With each volunteer tackling significantly different challenges, establishing a strong code control setup made our weekly reviews far easier.”
The team also used the opportunity to extend their Python skills, with a particular focus on GeoPandas, which enables some of the more intricate data transformations that are normally performed by mainstream desktop GIS tools.
Additionally, the group used this work to explore the concept of DAGs, directed acyclical graphs. This term refers to the building blocks of any pipeline: a recipe, or series of steps, that you apply to your data. There are scores of packages available to assist with pipeline development, but to start, the team decided to use a simple workflow management system called Snakemake. Snakemake works by using Makefiles to connect the expected input and output files across multiple pipeline stages. Although, in the end, the team decided it was not the best solution for scaling up to the real pipeline (which is now being developed with Airflow), they agreed that using Snakemake was a great stepping stone to becoming familiar with this key concept.
Working together
Finally, before COVID-19 hit, MapAction’s dedicated volunteers were accustomed to meeting in person once a month – a commitment that led to many enjoyable shared moments and close friendships. This positive and much-loved aspect of being a volunteer at MapAction has unfortunately been hindered by the pandemic. Although still conducted fully remotely, the slow data scramble offered the chance to regularly meet, share expertise, motivate and encourage each other, and work together. Volunteer Dominic Greenslade said it well: “MapAction volunteers are amazing people, and the ability to spend so much time getting to further these friendships was a great bonus”.
MapAction has been chosen as one of 202 organisations taking part in Google’s 2021 Summer of Code, a global programme that aims to bring student developers into open source software development. As part of the scheme, which has now entered into its 17th year, students can apply for placement projects from 202 open source entities, with their time paid for by Google. MapAction is one of 31 organisations taking part for the first time.
Since launching, over 16,000 students across 111 countries have taken part by working with an open source organisation on a 10-week programming project during their summer break from studies. Google Summer of Code is open to students who are age 18 and older and enrolled in a post-secondary academic programme in most countries. As MapAction is one of the only companies taking part from the humanitarian charity sector, it’s a great opportunity to highlight the importance of technology advances to our work.
As part of our Moonshot initiative, two students will be helping us with our goal of automating the production of core maps needed in any humanitarian crisis, for 20 priority countries. Being able to automate these maps means essential contextual and reference information about, among other things, the local environment, population and infrastructure, is immediately available when needed in the best possible quality. The students will be working with MapChef, our Python-based map automation tool, and our MVP pipeline framework for automated data acquisition and processing. As our capability grows, we intend to use these systems to identify data gaps at regional levels.
Take a look at our project ideas for the Google Summer of Code. Applications officially open on 29 March and we anticipate a lot of interest.
Although data science is still a relatively new field, its potential for the humanitarian sector is vast and ever-changing. We caught up with one of MapAction’s Data Scientists Monica Turner to discover how data science is evolving, the impact of COVID-19 on her work and how predictive modelling could see disaster funding being released before a disaster has occurred.
Interview by Karolina Throssell, MapAction Communications Volunteer
How did you get into data science?
I have a background in Astrophysics but wanted to transition into data science, so I started volunteering with 510 global which is part of the Netherlands Red Cross. This was my first experience in the humanitarian sector, and I was immediately hooked. After working briefly as a data scientist at a technology company, I began working at MapAction in March 2020. As part of my work, I am seconded to the Centre for Humanitarian Data in the Hague, which is managed by the United Nations Office for the Coordination of Humanitarian Affairs (OCHA).
What is the role of data science at MapAction?
Even though one of MapAction’s primary products is maps, these are created by combining different data sets. So, while the explicit presence of a data scientist at the organisation is new, MapAction has fundamentally always been doing data science on some level. With this new role, the hope is to both formalise the current data science practices, and expand our analytical capability, ultimately shifting our role from data consumer to having an active role in the development and improvement of humanitarian data sets.
As a data scientist, you often have to wear many hats – from data cleaning to model development to visualisation. With the Moonshot project, we are looking to automate the creation of seven to nine key maps for 20 countries. One of my first tasks is to design and build a pipeline that downloads, transforms, and checks the quality of all the different data sets that make up these key maps. The details of this pipeline will be the subject of a future blog post.
How has COVID-19 impacted on your work?
One of MapAction’s strengths is the field work that we are able to do during an emergency as well as the remote support we provide. However, as COVID-19 has limited the ability to travel, the paradigm has shifted and we need to rethink how we respond to emergencies overall. In particular, we are working to expand the types of products that we offer to our partners, as the demand increases for more remote-oriented products such as web-based dashboards.
At the Centre for Humanitarian data, in collaboration with the Johns Hopkins Applied Physics Laboratory, we’ve been developing a model relating to the spread of COVID, to help low- and middle-income countries plan their responses.
Photo: Trócaire
One of the main challenges of modelling COVID-19 is the novelty of the disease. Since there is no historical data, model validation becomes much more challenging. Additionally, the number of cases and deaths is a crucial input to the model. With higher income countries, more testing is done so the data we need is there, however the availability and quality of this data in low- and middle-income countries poses a further hurdle. Nevertheless, even with these caveats it is still very valuable to provide low- and middle-income countries with a tailored scenario-building tool for developing their COVID response.
Where is data science heading?
Predictive analytics will play a much larger role in the future of data science. The UN is currently working on a huge project to provide funding for predictive models that will enable it to release funding from the Central Emergency Response Fund (CERF), to help communities prepare and protect themselves from disasters before they occur. After a successful pilot project in Bangladesh, we plan to extend our model validation to other types of disasters such as cholera and food insecurity.
At MapAction, the Moonshot will lead a shift towards preparedness and enable us to develop methods to assess the completeness and quality of the data going into our maps. Our hope is that with this emphasis on data analysis, we will be able to provide meaningful contributions to a wide array of humanitarian data sets. Additionally, we are hoping to build an analytics team, and will be recruiting data science volunteers in early 2021, so check our website and sign up to our newsletter to find out how you can apply. And if you can contribute in other ways to our data science work, please contact us!
History will always underscore how landing on the moon represented a significant milestone in the space race, yet what is often less spoken about is the number of technologies that might not have ever made it without space travel.
These include the all-important ability to take pictures on our phone, thanks to the technology originally created by a team at the Jet Propulsion Laboratory, and the technique used to develop diamond-hard coatings for aerospace systems that can now be found on scratch-resistant spectacles. Inventions that originally started life with a bigger purpose but have filtered down into solving some of the challenges in our everyday lives.
This brings us onto MapAction’s own Moonshot initiative – an ambitious programme of work encompassing step changes in the way we use different technologies in the course of our work. This includes things like how we triage, assign and manage the requests for support we receive, and how we can automate certain repeat activities.
One of the first projects we are working on within the Moonshot programme will enable us to produce seven to nine key maps for 20 of the world’s most vulnerable countries automatically, using technology we’re developing that will provide benefits for many years to come. This is being funded through our partnership with the German Federal Foreign Office.
In the humanitarian sector, a perennial challenge is access to high-quality data. This need is even more acute in the chaotic aftermath of a humanitarian emergency, when data and maps are crucial to make rapid sense of the situation and plan the best response to save lives and minimise suffering.
In the early hours of a crisis, one of the first tasks facing our team is to produce standardised ‘core’ maps that will be used throughout the response, regardless of the nature of the emergency. These provide contextual and reference information about, among other things, the local environment, population and infrastructure. Sometimes they are created under difficult on-the-ground conditions or with incomplete information. Once they are in place, they are used to create additional situation-specific maps by layering on top evolving information about the extent and impacts of the emergency and the humanitarian response.
As MapAction has made maps in hundreds of emergencies, it has become apparent that, in creating these foundational core maps, there are many repeatable, generalised tasks that could be handled much more quickly by a machine, achieving in seconds what used to take hours. This would give humanitarian decision-makers the orientation information they need immediately, and free up our specialist volunteers for actively assessing and engaging with the situation at hand and performing the mapping tasks that only humans can do.
Moreover, by shifting the focus from reactive to proactive data sourcing and map production, we can ensure we provide the best maps possible – not just the best maps, given the time and data available and the prevailing circumstances in the midst of a humanitarian emergency.
Many countries, particularly low and middle-income countries, are likely to have data gaps, and they are often also the countries that may have the least resilience to emergencies such as droughts or earthquakes. Identifying and addressing these data gaps in advance is a big part of the Moonshot project, and something that will have benefits for the humanitarian sector as a whole.
Like the proverbial needle in the haystack, important data can exist within a subset of a much larger dataset and accessing it can be tricky. Finding a gap is even more difficult, as you’re looking for an unknown entity that isn’t there. The technology we’re developing for the Moonshot will help us to identify the hard-to-see data gaps and quality issues that currently exist. By discovering these, we can pinpoint what information will be needed to ensure a complete map and then work with partners around the world to proactively put in place missing data or improve what currently exists.
The initial goal of the Moonshot is to publish 180 core maps (nine for each of the 20 vulnerable countries identified at the beginning of the project). The same processes will then be applied to other countries and, eventually, to other types of automated maps beyond these core ones. This means we will ultimately be in a position to expand our understanding and quality assessment processes for more data types. New opportunities and routes of travel are likely to emerge as the project develops.
The ambition is big, but the possibilities that will result from achieving this goal will fundamentally change the way we approach map creation in the humanitarian sector in the future.
In a series of blogs over the next few months, we will share the story of this work as it unfolds, as well as diving down deeper into specific elements of it.






.jpg){kind=link}